
An Illustrated Guide to Bi-Directional Attention Flow (BiDAF)
Note: this article is also published on Towards Data Science. You might want to read it there for a better reading experience.
Introduction
The year 2016 saw the publication of Bi-Directional Attention Flow (BiDAF) by a team at University of Washington. BiDAF handily beat the best Q&A models at that time and for several weeks topped the leaderboard of the Stanford Question and Answering Dataset (SQuAD), arguably the most well-known Q&A dataset. Although BiDAF’s performance has since been surpassed, the model remains influential in the Q&A domain. The technical innovation of BiDAF inspired the subsequent development of competing models such as ELMo and BERT, by which BiDAF was eventually dethroned.
When I first read the original BiDAF paper, I was rather overwhelmed by how seemingly complex it was. BiDAF exhibits a modular architecture — think of it as a composite structure made out of lego blocks with the blocks being “standard” NLP elements such as GloVe, CNN, LSTM and attention. The problem with understanding BiDAF is that there are just so many of these blocks to learn about and the ways they are combined can seem rather “hacky” at times. This complexity, coupled with the rather convoluted notations used in the original paper, serves as a barrier to understanding the model.
In this article series, I will deconstruct how BiDAF is assembled and describe each component of BiDAF in (hopefully) an easy-to-digest manner. Copious amount of pictures and diagrams will be provided to illustrate how these components fit together. Here is the plan:
- Part 1 (this article) provides an overview of BiDAF.
- Part 2 will talk abut the embedding layers.
- Part 3 will talk about the attention layers.
- Part 4 will talk about the modeling and output layers. It will also include a recap of the whole BiDAF architecture presented in a very easy language. If you aren’t technically inclined or are short on time, I recommend you to directly jump to part 4.
This series was selected as featured articles by Towards Data Science.
BiDAF vis-à-vis Other Q&A Models
Before delving deeper into BiDAF, let’s first position it within the broader landscape of Q&A models. There are several ways with which a Q&A model can be logically classified. Here are some of them:
- Open-domain vs closed-domain. An open-domain model has access to a knowledge repository which it will tap on when answering an incoming Query. The famous IBM-Watson is one example. On the other hand, a closed-domain model doesn’t rely on pre-existing knowledge; rather, such a model requires a Context to answer a Query. A quick note on terminology here — a “Context” is an accompanying text that contains the information needed to answer the Query, while “Query” is just the formal technical word for question.
- Abstractive vs extractive. An extractive model answers a Query by returning the substring of the Context that is most relevant to the Query. In other words, the answer returned by the model can always be found verbatim within the Context. An abstractive model, on the other hand, goes a step further: it paraphrases this substring to a more human-readable form before returning it as the answer to the Query.
- Ability to answer non-factoid queries. Factoid Queries are questions whose answers are short factual statements. Most Queries that begin with “who”, “where” and “when” are factoid because they expect concise facts as answers. Non-factoid Queries, simply put, are all questions that are not factoids. The non-factoid camp is very broad and includes questions that require logics and reasoning (e.g. most “why” and “how” questions) and those that involve mathematical calculations, ranking, sorting, etc.
So where does BiDAF fit in within these classification schemes? BiDAF is a closed-domain, extractive Q&A model that can only answer factoid questions. These characteristics imply that BiDAF requires a Context to answer a Query. The Answer that BiDAF returns is always a substring of the provided Context.

An example of Context, Query and Answer. Notice how the Answer can be found verbatim in the Context.
Another quick note: as you may have noticed, I have been capitalizing the words “Context”, “Query” and “Answer”. This is intentional. These terms have both technical and non-technical meaning and the capitalization is my way of indicating that I am using these words in their specialized technical capacities.
With this knowledge at hand, we’re now ready to explore how BiDAF is structured. Let’s dive in!
Overview of BiDAF Structure
BiDAF’s ability to pinpoint the location of the Answer within a Context stems from its layered design. Each of these layers can be thought of as a transformation engine that transforms the vector representation of words; each transformation is accompanied by the inclusion of additional information.
The BiDAF paper describes the model as having 6 layers, but I’d like to think of BiDAF as having 3 parts instead. These 3 parts along with their functions are briefly described below.
- Embedding Layers
BiDAF has 3 embedding layers whose function is to change the representation of words in the Query and the Context from strings into vectors of numbers.
- Attention and Modeling Layers
These Query and Context representations then enter the attention and modeling layers. These layers use several matrix operations to fuse the information contained in the Query and the Context. The output of these steps is another representation of the Context that contains information from the Query. This output is referred to in the paper as the “Query-aware Context representation.”
- Output Layer The Query-aware Context representation is then passed into the output layer, which will transform it to a bunch of probability values. These probability values will be used to determine where the Answer starts and ends.
A simplified diagram that depicts the BiDAF architecture is provided below:
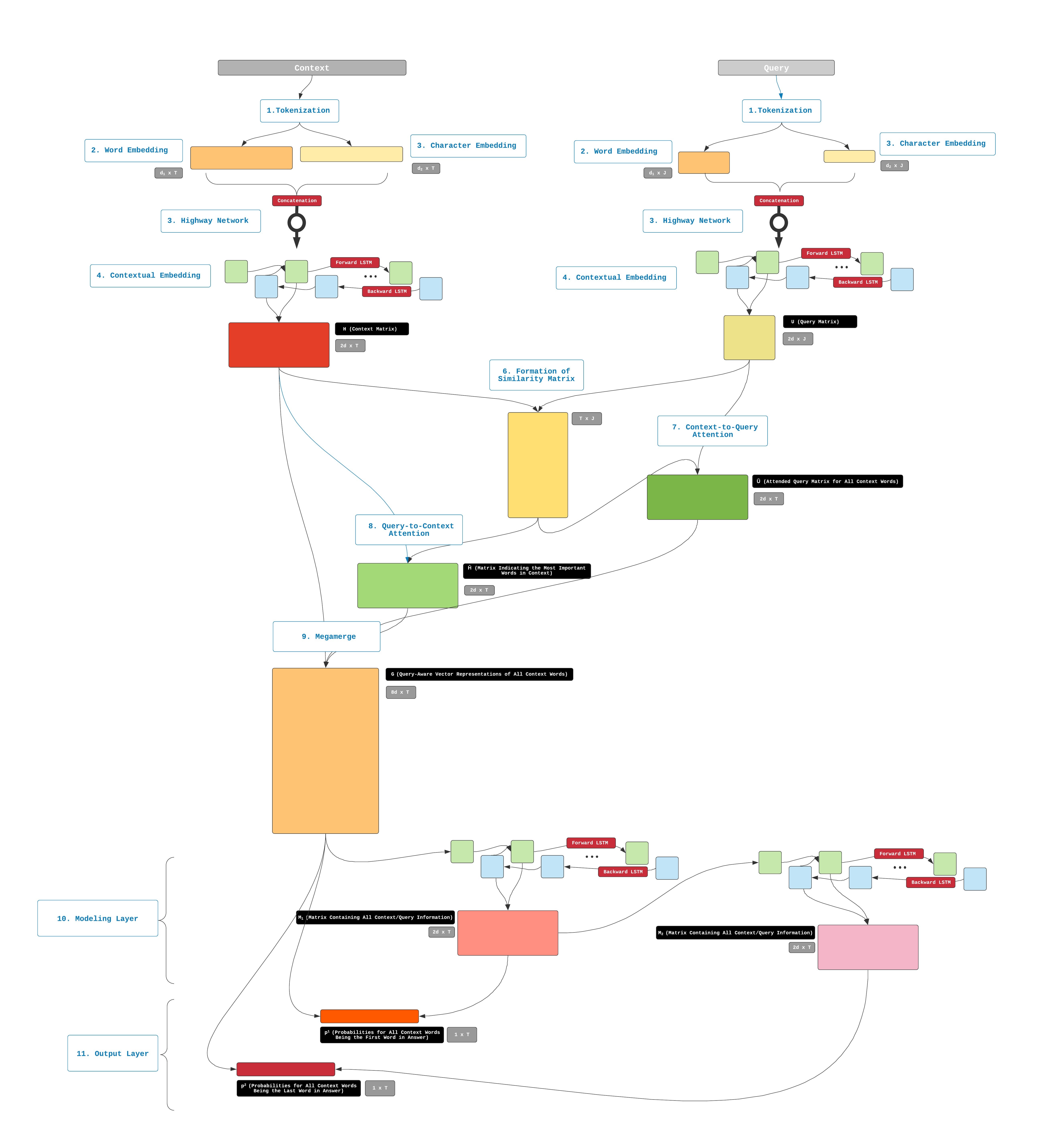
Architecture of BiDAF.
If all these don’t make sense yet, don’t worry; in the next articles, I will delve into each BiDAF component in detail. See you in part 2!
Leave a comment