
Interview with Apache Pig: Theory and Practical Guide
Apache Pig is an integral component of the Hadoop ecosystem. Since his birth more than a decade ago, he has helped thousands of analysts around the world make sense of massive data sets. Despite his importance, few people outside of the big data sector have heard of him, and some who are acquainted with him have only vague idea about his usage. A few days ago, I had the pleasure to sit down and talk with Apache Pig himself. Our discussion covered many topics — from his founding philosophy to practical guidance on writing his language, Pig Latin. Below is the excerpt of this interview. You can find a copy of this article in Towards Data Science.
Hi Pig! Thank you for this interview opportunity!
Thank you! It’s my pleasure to give this interview and gain some additional exposure for myself. You know, I’m tired of people confusing me with my buddies in the Hadoop ecosystem. To many, we are just a mishmash of colorfully-named tools that somehow fit together to facilitate the management of Big Data. This has got to change! We play distinct roles in the Hadoop ecosystem and a familiarity with each of us is key to understanding Big Data. It’s about time that I cleared this confusion and told the world who I really am!
C'est moi - Apache Pig!
Great, that’s exactly what I’m here for! Now for the sake of our casual readers who are just getting started to the world of Big Data, could you please introduce yourself?
Of course! My name is Apache Pig, but most people just call me Pig. I am an open-source tool for analyzing large data sets.
I was conceived by Yahoo in 2006. My conception was driven by Yahoo’s need to transform and analyze massive amount of data without having to write complex MapReduce programs. In 2007, Yahoo open-sourced me under Apache Software Foundation (hence my first name). Since then, I have been guzzling and analyzing petabytes worth of data all around the world.
I like your name! Can you elaborate on its origin?
Thanks! It is an interesting name, isn’t it? Many people think that my name stems from my creators’ effort to stick to the animal theme that permeates the Hadoop world. This is partly true — my name was indeed inspired by the eponymous animal🐷. This name, in turn, led to the adoption of cute nomenclatures for concepts related to me such as Pig Latin —my programming language— and Grunt —my interactive shell (more on these later).
Apache Pig’s similarity to this cute fella is more than skin deep!
However, apart from it being catchy, there is actually an interesting philosophy that underlies my name. This philosophy, which is somewhat related to the characteristics of pig the animal, consists of four principles that guide how I should be developed:
- Pigs eat anything. I am a voracious data-guzzler. I can process any type of data, be it relational, flat, nested, structured or unstructured. I’m also capable of reading data from multiple sources, such as Hive, HBase and Cassandra.
- Pigs live anywhere. Although I was first implemented on Hadoop, I’m not intended to be tied to this framework. For instance, I can be run in a single computer to analyze local files.
- Pigs are domestic animals. I was designed to be easily understandable and modifiable by users. My programming language, Pig Latin, is easy to wrap one’s head around. In addition, its capabilities can be easily extended by importing various user defined functions (UDFs).
- Pigs fly. This motto speaks to the speed with which I can process data. It also embodies my ability to help my users express complex logic in just a few lines of Pig Latin code.
That’s very interesting. Now, you mentioned that you are part of the Hadoop ecosystem. Can you tell us a bit about how you fit in this ecosystem?
Certainly! To start off, for the sake of those who are new to this field, let me give you a quick explanation about Hadoop.
Hadoop is a collection of open-source tools with which we can harness the combined power of several computers to store and process massive amounts of data.
The diagram below depicts how I relate to other components within the ecosystem.

Pig and other Hadoop components
The core of Hadoop is HDFS (Hadoop Distributed File System) and YARN (Yet Another Resource Negotiator). I work closely with these two guys.
HDFS is a distributed storage system. It breaks files into blocks, makes redundant copies of these blocks and distributes them across different machines in the cluster. You can think of HDFS as my data manager. I read input files from HDFS, temporarily store my intermediate calculation results in HDFS and write the output of my analysis to HDFS.
On the other hand, you can think of YARN as my computing resource manager. YARN negotiates computing resources on my behalf and schedules the tasks I need to execute. In doing so, YARN works closely with HDFS. YARN makes sure that the computing resources I get are located close (in terms of network topology) to the machines that store the data that I have to analyze.
In the diagram above, I see that there is an execution engine layer between YARN and yourself. Could you explain what an execution engine is?
Good question! YARN is actually as my indirect computing resource manager — I don’t interface directly with him. Instead, this interaction takes place through an execution engine layer. In Hadoop’s context, an execution engine is a software system or a framework that runs across a cluster and gives the illusion of the cluster being a single giant machine. Most execution engines run on top of YARN. As of today, there are three execution engines I can run on: MapReduce, Tez and Spark.

The three execution engines that Pig can run on: Hadoop, Tez and Spark.
You’ve previously singled out MapReduce and said that you obviate the need for writing MapReduce code. Can you elaborate more on what MapReduce is?
Sure! As I mentioned earlier, MapReduce is one of the three execution engines that I can run on. It is not a piece of software per se; rather, it is a simple yet powerful programming paradigm (i.e. a way of designing a program). Every MapReduce program consists of three phases: map, shuffle, and reduce.
I shall first define these terms conceptually. Suppose we have a giant file on which we’d like a MapReduce program to operate. In the map phase, the program will look at this giant file line by line. For each line, the program will output a key-value pair. The exact identity of these keys and values will depend on the objective of the program.
In the shuffle phase, the key-value pairs with the same keys are grouped together. The resulting groups will be ordered according to their keys (e.g. if the keys are strings, then the groups will be sorted by the alphabetical structure of the keys). The output of the shuffle phase is an ordered bunch of groups. These groups are then distributed to different machines for the subsequent reduce phase.
In the reduce phase, an aggregation function is applied to the bundled values in each group produced in the shuffle phase. This process is performed in parallel in many machines. The reduce phase will output the result of the program.
An example will make this clearer. Let’s say I have a text file and I want to count the occurrence of each distinct word in the text. Here is how a MapReduce job for this task would look like:
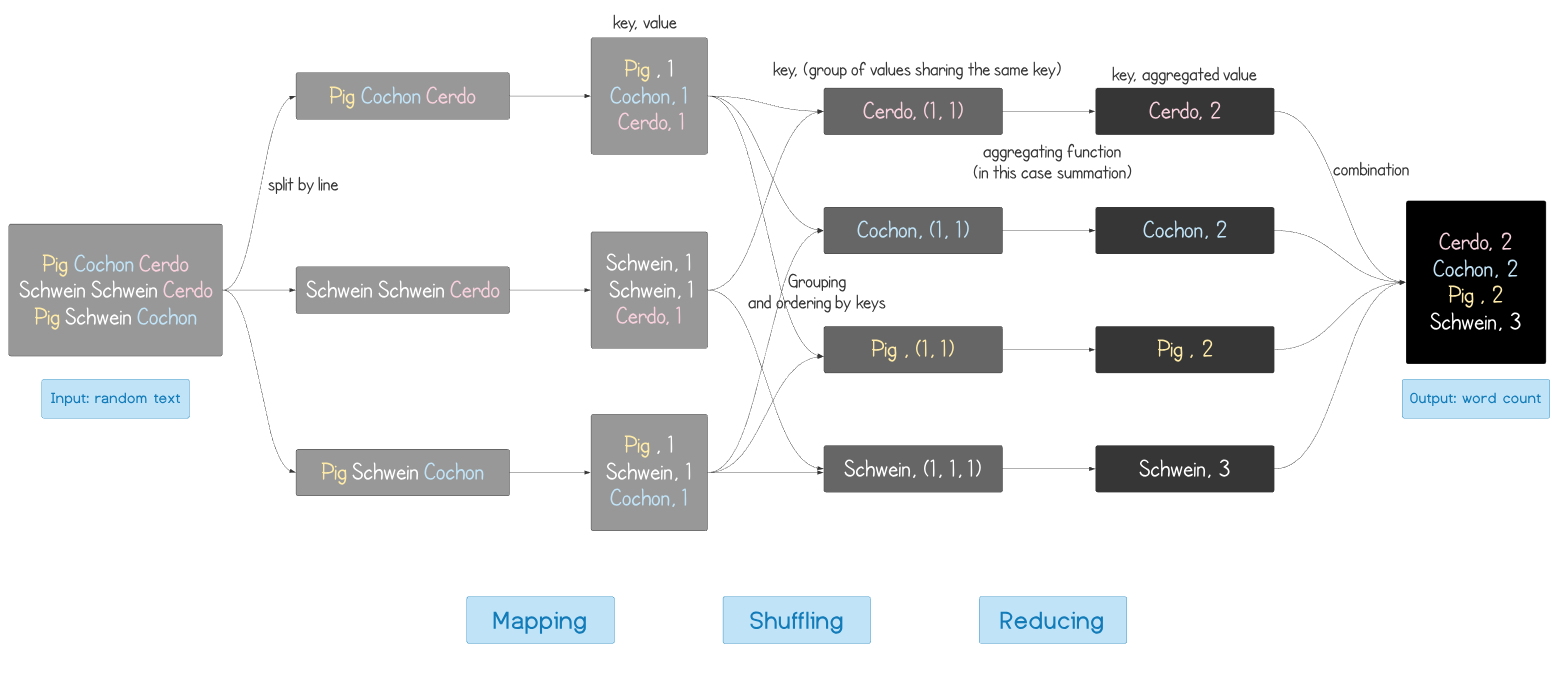
MapReduce for word count
The above example looks simple, doesn’t it? Unfortunately, this is not the case for a great majority of MapReduce programs! Any big data professional can tell you that writing MapReduce programs is cumbersome and that not all data procedures can be easily written using the MapReduce paradigm. This is where I come in! It turns out that my language, Pig Latin, is much easier to write than MapReduce (one estimate points out that 10 lines of Pig Latin are equivalent to 200 lines of MapReduce code in Java!). When I run on MapReduce as the execution engine, under the hood, all these Pig Latin codes are converted into their MapReduce programs. Pretty neat, huh?
Cool! What about the two other execution engines, Tez and Spark? Are they similar to MapReduce?
Not quite! The MapReduce paradigm requires that a program be broken down into a series of mapping and reducing tasks. This requirement can sometimes lead to a convoluted program that consists of a long linear series of mappers and reducers.
On the other hand, when I run on either Tez or Spark, I will convert the logic expressed in a Pig Latin code into a data structure known as Directed Acyclic Graphs (DAGs). The word “directed” in DAG means that all the data flow to one direction, while the word “acyclic” means that DAGs can’t contain any loop. Here is an illustration of DAG:
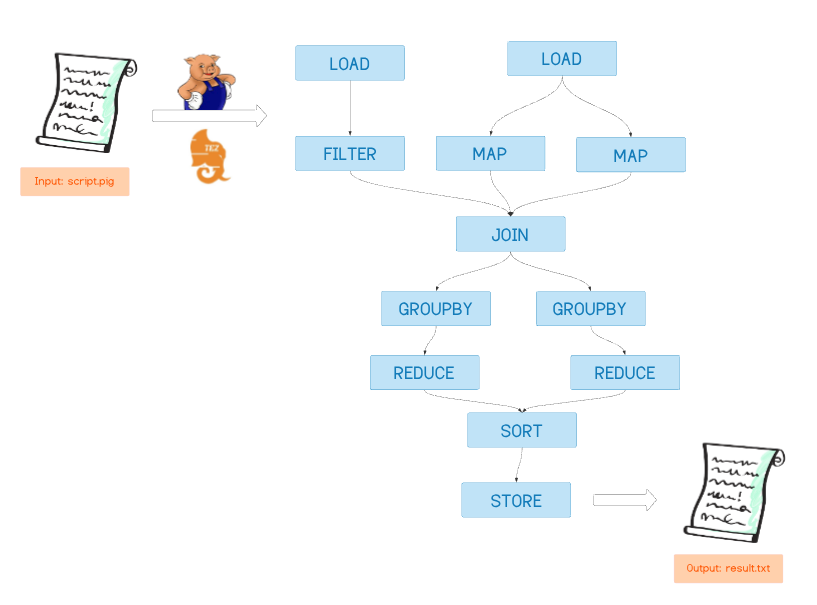
Example of DAG
When creating a DAG, I will ensure that the steps are ordered in a way that optimizes computation. For example, let’s say we have a script that contains a JOIN operation followed by a FILTER step. I will investigate whether the ‘FILTER’ step can be done before the ‘JOIN’ step. If yes, I will perform the FILTER step prior to the JOIN step, thus reducing the number of data points to be joined (JOIN is a computationally expensive operation!). Because of the power of DAGs, my running on Tez or Spark always leads to better performance compared to MapReduce.
Dope! Now let’s talk about your use case. You told me that you facilitate the analysis of Big Data. Could you go into specifics — what are scenarios where someone should use you?
In my experience, people use me for two things: extract-transform-load (ETL) pipelines and ad-hoc queries.
A typical ETL pipeline loads in a data from a source, clean it, transform it and store it somewhere. An example is the processing of log data of a particular website. Using my FILTER function, one can clean these logs by filtering out data coming from automatic bots and internal views. I can also perform transformations that enrich the original log data. For instance, I can group these log data by the countries that the visitors hail from to provide more fine-grained view of the data.
My other common use case is research and ad-hoc queries. Traditionally, these are done using SQL. However, if the data set to be queried is unstructured and contains “complications” such as nested structures and missing values, I may be a better tool. My flexibility and extendability lend themselves well for such cases.
That sounds a whole lot like what your friend Hive can do, too. What’s the difference between you and Hive?
This is a question I receive a lot. Before I go into the details, let me quickly introduce Hive 🐝 to you. Like myself, Hive is a data analysis tool that is part of the Hadoop ecosystem and can run on either MapReduce, Tez or Spark.

Pig and Hive
- Language. Hive uses HiveQL, a variant of the familiar query language a programming language SQL while I use Pig Latin, a procedural language. Pig Latin is more extendable than SQL — one can import Python or Java functions to broaden Pig Latin’s functions. There are other differences between Pig Latin and SQL, which I will elaborate later.
- Input data. Hive imposes schema on the data it processes, thus can only handle structured data. Meanwhile, as I mentioned before, I can handle structured, semi-structured or unstructured data.
- Target user. Because Hive uses a language similar to standard SQL, it is targeted for users who are already comfortable with the latter, namely data analysts. These data analysts mainly use Hive for periodic reporting. Meanwhile, Pig Latin is more powerful but takes a bit more time to get used to. As such, I am more suited to programmers, data engineers and researchers that can apply me for the use cases I mentioned previously.
Ok, we have talked quite a bit about your strengths and use cases. I don’t want to sound like a clueless HR guy, but I have a rather uncomfortable question that I believe to be of interest to our readers. What are your weaknesses?
Ah I see, the dreaded “weakness” question 😓. Well let me be frank — I do have some limitations that might make me unsuitable in some cases. Here are my main limitations:
- My language, Pig Latin, is a procedural language that describes data transformation. It does not natively support loops and only have limited support for
IF/THENconstructs, which are sometimes necessary. - I can only perform basic data analysis and can only return textual/numerical results. If you want to perform more sophisticated data exploration, such as ones that involve making visualizations, or build a machine learning model, then I am not the right guy! For this, my buddy Spark will be more appropriate.
- Lastly, I am rather slow 😓 and thus not suitable for low latency queries.
That brings me to my next awkward question. Word has it that some people are ditching you in favor of Spark. What say you?
Sadly, this is true. Spark is quickly gaining ground in the industry. In the rapidly evolving Big Data sector, it is only natural that the community regularly phases out older technologies in favor of newer, more powerful tools. To my chagrin, it feels that I am the one currently being phased out 😭.

Relative interest in Pig vs Spark as indicated by Google searches of these terms
Let me quickly tell you why Spark is in many ways superior to myself. While my language Pig Latin provides several high-level operators and is extendable to a certain extent, Spark is a full-blown programming language. Thanks to tight integration to its “host” language (usually Scala or Python), Spark comes with complete control statements and unlimited ability to define functions and objects. All these allow you to transform your data in almost any way you like!
Relative interest in Pig vs Spark as indicated by Google searches of these terms
On top of that, Spark also has several libraries that can perform specialized procedures on massive data sets. For example, Spark’s MLlib allows for pre-processing, model training and making predictions at scale. With these abilities, Spark serves as a unified platform for the processing and analysis of Big Data. These are all things that are out of my reach!
Thank you for your honesty! Well, although you might now be slightly outdated, you are still an integral component in many legacy systems…
Ok, now let’s talk application. Let’s say someone is interested in using you. Where do they start?
I’d recommend them to download Hortonworks Data Platform (HDP) Sandbox. The HDP Sandbox is a pre-configured learning environment that contains the latest developments from Apache Hadoop, including myself! The Sandbox comes packaged in a virtual environment that one can run in their personal machine, allowing them to get a hold of me in no time.
A screenshot of Ambari, the dashboard-interface of HDP
Once you download the Sandbox, you can run me through a couple of ways:
- You can run me interactively using the Grunt shell. After ssh-ing to your Hadoop environment, simply type pig in your terminal to launch Grunt. Once Grunt is activated, you can start exploring Pig Latin by entering one line at a time.

- You can run a pig script. A pig script is just a text file that contains a series of Pig Latin commands. To run a script, you can simply type pig followed by the path to your Pig script.
- Pig View. Earlier versions of HDP (e.g. HDP 2.6.5) provides a web-UI called Pig View in which you can interactively run Pig Latin commands or scripts.
Pig View in Ambari
Cool! Now it’s time to talk about Pig Latin, your language. Can you give us some pointers about this language?
Sure! Pig Latin is a relatively simple scripting language. Through Pig Latin, users can command me to perform common data operations such as SELECT,JOIN and FILTER. Pig Latin is also extendable; users can develop and import UDFs to expand Pig Latin’s capability.
Here is an example of Pig Latin. The script below is the Pig Latin equivalent of the MapReduce program we saw earlier, which counts the occurrence of each distinct word in a text file. Take a look:
lines = LOAD 'sourcefile.txt' AS (line:chararray);
words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) as word;
grouped = GROUP words BY word;
wordcount = FOREACH grouped GENERATE group, COUNT(words);
STORE wordcount INTO 'result.txt';
Hmm… It looks a bit like SQL…
That seems to be a common opinion among my users — that Pig Latin is a procedural version of SQL. I don’t necessarily agree with this view. Although there are certain similarities, there are also some salient differences.
SQL is a descriptive language. It lets users describe the information (i.e. the table) they need and will get it for them. Pig Latin, on the other hand, is a procedural language. In Pig Latin, users have to specify the steps that will lead them to their desired table (or relation, in Pig Latin terminology). The procedural nature of Pig Latin commands an advantage: by forcing users to write each step atomically, Pig Latin reduces the risk of conceptual bugs that often creep up in complicated SQL scripts.
While we are on the topic of language comparison, let me quickly point out that Pig Latin has also been described to be rather similar to Python’s Pandas 🐼. Such a comparison stems from the fact that both Pig Latin and Pandas are procedural languages. IMO, we shouldn’t overstate the similarity of the two — Pandas is a much more powerful language equipped with extensive in-built functions and easy integration to Numpy and other Python tools. However, on the basic level, Pig Latin does have some overlap with Pandas.
I think it is great that Pig Latin is similar to SQL and pandas—two languages with which most data analysts are already familiar. This overlap supports your earlier claim that you are easy to use! Do you have any source that compares Pig Latin and the two?
Certainly! In the table below, I have listed out common Pig Latin commands and their equivalents in SQL and Pandas. Do note that all there are lots and lots of variations to all these commands that can be invoked with different keywords and arguments, and the ones I show are just one possibility.
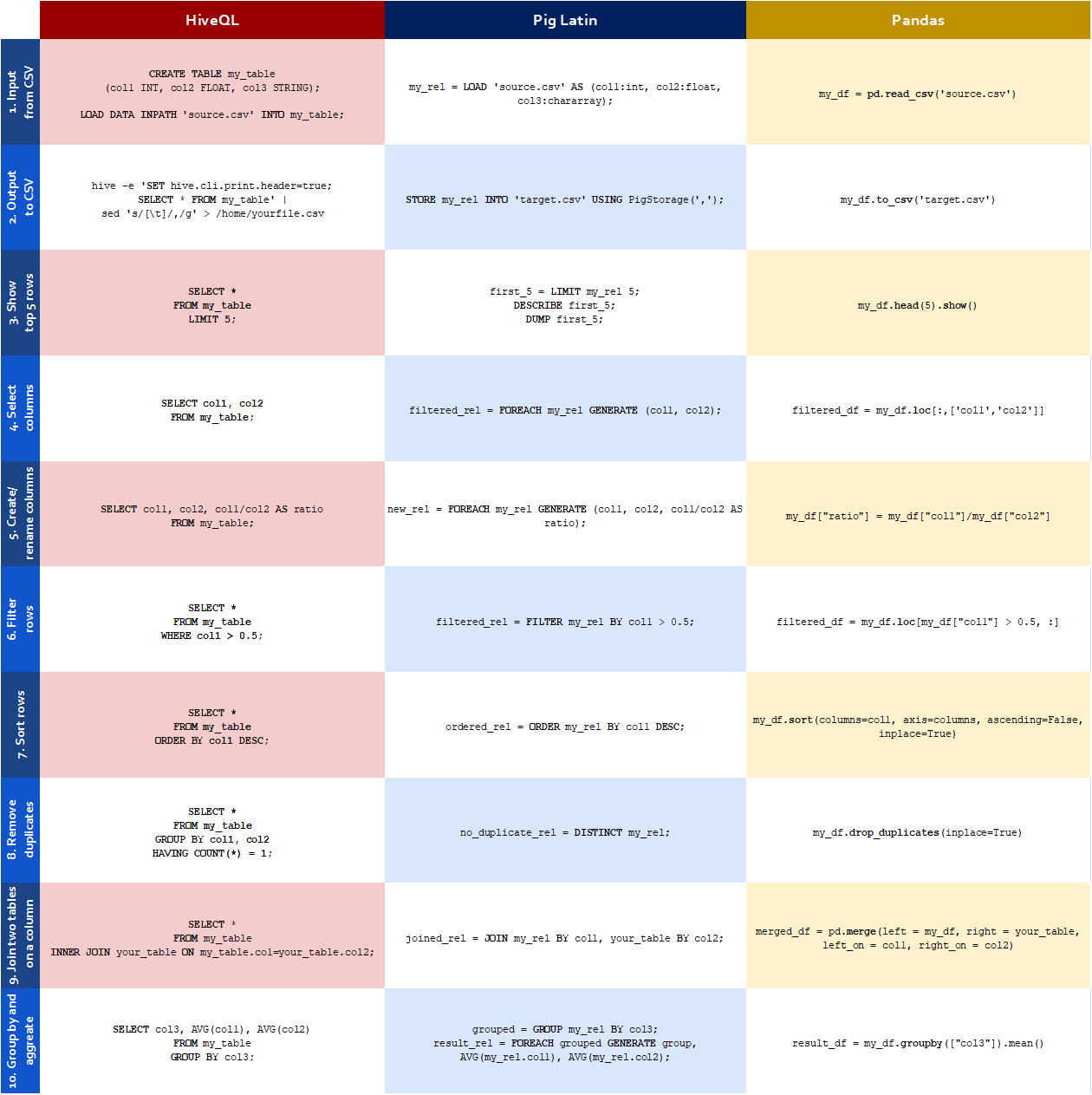
Common commands in Pig Latin and their SQL/Pandas equivalents
Wow, that’s awesome! That table will certainly help people who are familiar with SQL or Pandas get up to speed with writing Pig Latin!
Yep, that is my hope when I compiled that table 😇. —
Well Pig, this has been a rather long interview. To conclude our talk, do you have any last message for our readers?
Sure! I hope that our conversation has given insight into who I am and how I fit in the Hadoop ecosystem. Although I may no longer be the sexiest Big Data tool in the market, I am still widely used in the industry and academia. I hope you will take the time to learn to use me 🙂.However, if you are pressed for time and want to simply master a single, Swiss-army-knife tool that can be applied to a wide range of Big Data problems, Spark might be your best bet.
I hope you enjoyed the interview. In case you were wondering, I supplied both sides of the above dialogue. The personification of Apache Pig was intended to facilitate learning and this character does not in any way represent the opinions of the creators of Apache Pig. If you have any questions/comments about the article or would like to reach out to me, feel free to email at meraldo.antonio AT gmail DOT com.
Leave a comment